- 软件



/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
/中文/
/中文/

/中文/
 7-zip下载v18.03 简体中文美化版
7-zip下载v18.03 简体中文美化版 Bubble Math(泡泡数学)v1.0 电脑版
Bubble Math(泡泡数学)v1.0 电脑版 EditPad Pro(多功能文本编辑器)v7.65 中文版
EditPad Pro(多功能文本编辑器)v7.65 中文版 Easy Equation Solver(在线方程式计算器)v1.8 官方版
Easy Equation Solver(在线方程式计算器)v1.8 官方版 ScanTransfer(无线传输工具)v2018 官方版
ScanTransfer(无线传输工具)v2018 官方版 彗星QQ资源文件读取器v2.1 绿色免费版
彗星QQ资源文件读取器v2.1 绿色免费版 Flash Renamer(批量重命名软件)v6.9 官方版
Flash Renamer(批量重命名软件)v6.9 官方版 动书编辑器(motionbook)v2018 官方版
动书编辑器(motionbook)v2018 官方版 字由客户端v2.0.0.4 官方版
字由客户端v2.0.0.4 官方版 Notepad2书签版(Notepad2 Bookmark Edition)v5.1 官方版
Notepad2书签版(Notepad2 Bookmark Edition)v5.1 官方版软件Tags: ApacheNutch编程工具
Apache Nutch是一款用于java编程工具的搜索引擎软件,快速完成java数据编程,智能检索java资源便捷使用。快来绿色资源网下载体验吧!
Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,这两大分支最大的区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术。Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎.
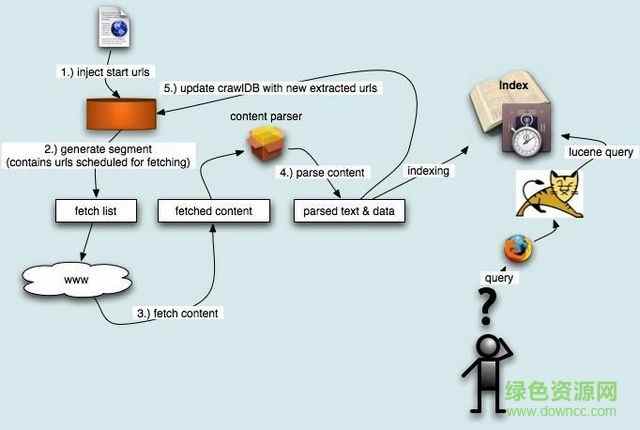
在创建一个WebDB之后(步骤1), “产生/抓取/更新”循环(步骤3-6)根据一些种子URLs开始启动。当这个循环彻底结束,Crawler根据抓取中生成的segments创建索引(步骤7-10)。在进行重复URLs清除(步骤9)之前,每个segment的索引都是独立的(步骤8)。最终,各个独立的segment索引被合并为一个最终的索引index(步骤10)。
其中有一个细节问题,Dedup操作主要用于清除segment索引中的重复URLs,但是我们知道,在WebDB中是不允许重复的URL存在的,那么为什么这里还要进行清除呢?原因在于抓取的更新。比方说一个月之前你抓取过这些网页,一个月后为了更新进行了重新抓取,那么旧的segment在没有删除之前仍然起作用,这个时候就需要在新旧segment之间进行除重。
 Redis Assistant(可视化管理监控工具)v1.0.0 免费版编程开发 / 3.9M
Redis Assistant(可视化管理监控工具)v1.0.0 免费版编程开发 / 3.9M
 Resource Hackerv5.1.8 绿色版编程开发 / 2.1M
Resource Hackerv5.1.8 绿色版编程开发 / 2.1M
 Interbase数据库编程开发 / 248.5M
Interbase数据库编程开发 / 248.5M Markdown Monster编程开发 / 21.7M
Markdown Monster编程开发 / 21.7M 小码精灵编程电脑客户端编程开发 / 172.1M
小码精灵编程电脑客户端编程开发 / 172.1M PHP Manager for IIS 7(IIS7配置PHP)编程开发 / 486KB
PHP Manager for IIS 7(IIS7配置PHP)编程开发 / 486KB 信捷XC系列PLC编程软件(XCPPro)编程开发 / 6.6M
信捷XC系列PLC编程软件(XCPPro)编程开发 / 6.6M 核桃编程电脑版编程开发 / 209.3M
核桃编程电脑版编程开发 / 209.3M Appeon Powerbuilder 2021编程开发 / 1.66G
Appeon Powerbuilder 2021编程开发 / 1.66G DBeaver数据库连接工具编程开发 / 89.8M
DBeaver数据库连接工具编程开发 / 89.8M TGraphDisplay3D(图形编程软件)v1.0.59.202 官方版编程开发 / 23.2M
TGraphDisplay3D(图形编程软件)v1.0.59.202 官方版编程开发 / 23.2M Sencha Architect 3注册版编程开发 / 240.7M
Sencha Architect 3注册版编程开发 / 240.7M Mongood(MongoDB管理工具)v0.6.2 免费版编程开发 / 9.2M
Mongood(MongoDB管理工具)v0.6.2 免费版编程开发 / 9.2M Claris FileMaker Pro(低代码开发工具)v19.3.1.43 免费版编程开发 / 289.9M
Claris FileMaker Pro(低代码开发工具)v19.3.1.43 免费版编程开发 / 289.9M SRPG Studio(RPG游戏制作引擎)v1.149 免费版编程开发 / 191.5M
SRPG Studio(RPG游戏制作引擎)v1.149 免费版编程开发 / 191.5M sublime text3中文破解版(代码编辑器)编程开发 / 45.6M
sublime text3中文破解版(代码编辑器)编程开发 / 45.6M navicat data modeler3破解版(数据库设计)编程开发 / 110.4M
navicat data modeler3破解版(数据库设计)编程开发 / 110.4M CudaText代码编辑器v1.134.1.0 中文版编程开发 / 26.1M
CudaText代码编辑器v1.134.1.0 中文版编程开发 / 26.1M jsonbuddv6.0.0.0 官方版编程开发 / 20.3M
jsonbuddv6.0.0.0 官方版编程开发 / 20.3M infragistics2020破解版编程开发 / 2.04G
infragistics2020破解版编程开发 / 2.04G









 dyned电脑版(戴耐德英语软件)教育学习
dyned电脑版(戴耐德英语软件)教育学习 360游戏大厅v3.8.7.1021 最新版游戏平台
360游戏大厅v3.8.7.1021 最新版游戏平台 数独计算器v1.2 免安装版教育学习
数独计算器v1.2 免安装版教育学习 tl wr710n升级固件v1.130415官方版路由器类
tl wr710n升级固件v1.130415官方版路由器类 My Secret Folder(文件夹加密工具)加密解密
My Secret Folder(文件夹加密工具)加密解密 蓝蚂蚁qq金牌网吧破解版20175.7 免费版其他应用
蓝蚂蚁qq金牌网吧破解版20175.7 免费版其他应用 加密魔镜加密解密
加密魔镜加密解密 播客录播助手v2.3.0.1 官方版屏幕录像
播客录播助手v2.3.0.1 官方版屏幕录像 鲁ICP备2021036634号-4
鲁ICP备2021036634号-4